Ở 2 bài viết trước ([ML] Classification – Part 1 và [ML] Classification – Part 2) tôi đã giải thích rất nhiều về định nghĩa của “Classification” trong Machine Learning rồi, ngoài ra thì thuật toán rất nổi tiếng “k-nearest neighbors” cũng đã được phân tích khá chi tiết.
Thuật toán “k-nearest neighbors” này được sử dụng rất rộng rãi trong nghiên cứu khoa học. Tuy nhiên nó cũng là 1 thuật toán cũ kỹ rồi. Từ khi nó được ra đời, các nhà khoa học đã không ngừng phát triển các thuật toán khác phức tạp và mạnh mẽ hơn. Thuật toán tiếp theo mà tôi sẽ giới thiệu ở bài viết này là “Random Forest”.

Random Forest là 1 thuật toán còn khá mới mẻ (10 năm tuổi) tuy nhiên nó đã tạo ra 1 cuộc cách mạng trong Machine Learning: Random Forest phức tạp hơn k-nearest neighbors, nhưng lại nhanh hơn rất nhiều khi tính toán với máy tính. Ngoài ra Random Forest có độ chính xác cao hơn rất nhiều lần so với k-nearest neighbors. Nhắc đến”độ chính xác”, có nghĩa là khi các nhà khoa học kiểm thử thuật toán (bao gồm cả Iris dataset), thì Random Forest đưa ra nhiều câu trả lời chính xác hơn k-nearest neighbors.
Ramdom Forest là thành viên trong chuỗi thuật toán “decision tree”. Nhưng thế nào là decision tree (Cây quyết định)? Rất đơn giản, Trong lý thuyết quyết định (chẳng hạn quản lí rủi ro), một cây quyết định là một đồ thị của các quyết định và các hậu quả có thể của nó (bao gồm rủi ro và hao phí tài nguyên). Cây quyết định được sử dụng để xây dựng một kế hoạch nhằm đạt được mục tiêu mong muốn. Các cây quyết định được dùng để hỗ trợ quá trình ra quyết định. Cây quyết định là một dạng đặc biệt của cấu trúc cây.
Trong lĩnh vực máy học, cây quyết định là một kiểu mô hình dự báo (predictive model), nghĩa là một ánh xạ từ các quan sát về một sự vật/hiện tượng tới các kết luận về giá trị mục tiêu của sự vật/hiện tượng. Mỗi một nút trong (internal node) tương ứng với một biến; đường nối giữa nó với nút con của nó thể hiện một giá trị cụ thể cho biến đó. Mỗi nút lá đại diện cho giá trị dự đoán của biến mục tiêu, cho trước các giá trị của các biến được biểu diễn bởi đường đi từ nút gốc tới nút lá đó. Kỹ thuật học máy dùng trong cây quyết định được gọi là học bằng cây quyết định, hay chỉ gọi với cái tên ngắn gọn là cây quyết định.
Quay trở lại với ví dụ hoa Iris của chúng ta. Bảng dưới đây mô tả 1 ví dụ rất đơn giản về việc sử dụng cây quyết định để xác định giống loài của động vật. Để đơn giản hơn, chúng ta chỉ xem xét 1 vài giống loài thôi. Ok, giả sử rằng bạn nhìn thấy 1 động vật mà không biết giống loài của nó? Trong trường hợp này, bạn có thể sử dụng cây quyết định để tìm.
Việc thực hiện sẽ diễn ra qua các bước sau:
- Bắt đầu từ câu hỏi đầu tiên, trên cùng ở cây quyết định (Vòng tròn đỏ)
- Trả lời các câu hỏi về động vật và đi dần xuống phần dưới của cây, dựa vào câu trả lời của bạn (trả lời Có hoặc Không cho câu hỏi đầu tiên).
- Lặp lại các bước trên cho đến hết cây.
- Câu trả lời chính là kết quả cuối cùng của lá cây mà bạn đang dừng lại (leaf – Vùng màu xanh lá cây)

Đi sâu vào 1 ví dụ cụ thể: Khi tôi nhìn thấy một con vật mà tôi không biết, câu hỏi đầu tiên sẽ là: “Nó có lông không”? Giả sử con vật này có lông, tôi sẽ đi theo nhánh bên phải. Câu hỏi tiếp theo “Nó nặng bao nhiêu?” Giả sử rằng nó nặng 3KG đi, tôi sẽ đi tiếp theo nhánh bên trái. Nhìn vào bảng kết quả trên, tôi đã có câu trả lời cuối cùng “Đó là con gà.”
Ok, giờ chắc hẳn các bạn đã hiểu về Cây quyết định rồi chứ?
Quay trở về với thuật toán Random Forest: Ý tưởng của Random Forest rất đơn giản. Thuật toán sẽ tạo ra một vài cây quyết định (nói chung tầm vài trăm cái) và sẽ sử dụng chúng. Các câu hỏi của Cây quyết định sẽ là các câu hỏi cho từng thuộc tính. Ví dụ “Nếu lá hoa dài hơn 1.7 cm”, thì câu trả lời (ở khung màu xanh) sẽ là Lớp (ví dụ: Loài hoa). Chú ý rằng việc sử dụng vài trăm cây quyết định là bất khả thi với con người, nhưng đối với máy tính thì không thành vấn đề.
Vậy làm thế nào để tạo ra Cây quyết định?
Có 2 giải pháp chính:
- Tham khảo ý kiến của các chuyên gia (ví dụ Taxonomy trong trường hợp các giống Loài). Đây là 1 giải pháp hữu hiệu, tuy nhiên không phải lúc nào bạn cũng kiếm được chuyên gia để giải quyết vấn đề của bạn. Ngoài ra bạn cũng sẽ phải ngạc nhiên bởi các chuyên gia cũng sẽ phải gặp vấn đề như bạn. Ngoài ra không phải chuyên gia là không mắc phải lỗi lầm, ví dụ về việc phân loại giống loài, rất có thể chuyên gia cũng sẽ quên rằng Đà Điểu con có thể nặng hơn 50kg.
- Thay vì đó, các nhà khoa học sử dụng cách thứ 2: tạo thuật toán để tự xây dựng cây quyết định. Điều kiện duy nhất là máy tính cần có 1 vài ví dụ để tham khảo và học tập. Trong Iris dataset, các ví dụ là các bông hoa mà chúng ta đã biết rõ Loài của chúng.
Để tạo mới cây quyết định, thuật toán Random Forest luôn luôn bắt đầu với 1 cây quyết định rỗng. Đó là cây quyết định chỉ có điểm bắt đầu màu đỏ, mà liên kết thẳng tới câu trả lời (khung màu xanh). Tất nhiên là không thể để nó như thế được, thuật toán sẽ tìm ra câu hỏi đầu tiên tốt nhất để bắt đầu, và sau đó xây dựng cây quyết định. Trong ví dụ của chúng ta, câu hỏi đầu tiên là “Nó có lông không?”. Mỗi khi thuật toán tìm được 1 câu hỏi tốt để hỏi, nó sẽ tạo ra 2 nhánh (trái và phải) của cây. Khi không còn câu hỏi nào thú vị nữa, thuật toán sẽ dừng lại và kết thúc quá trình xây dựng cây quyết định.
Cách để tìm được câu hỏi tốt nhất thì khá là phức tạp, tuy nhiên tôi sẽ cố gắng giải thích cho các bạn hiểu về ý tưởng: Khi thuật toán bắt đầu chạy, nó sẽ không biết cách phân biệt các giống loài, hay nói cách khác, tất cả các giống loại đều thuộc cùng “1 giỏ”. Để tìm được câu hỏi đầu tiên tốt nhất, nó sẽ cố gắng thử hết tất cả các câu hỏi có thể (có thể có rất nhiều, đôi khi là vài triệu câu hỏi). Ví dụ “Có bao nhiêu mắt”, “Có bao nhiêu chân”, “Có lông không”, … Sao đó ứng với mỗi câu hỏi, nó sẽ xác minh câu hỏi này có dùng được để phân loại giống loài cho các đối tượng cần theo dõi không?. Câu hỏi được chọn không cần thiết phải quá hoàn hảo, nhưng nó nên tốt hơn các câu khác. Để xác định thế nào là câu hỏi tốt, thuật toán sẽ tính toán “information gain”. Tôi sẽ không đi quá sâu về vấn đề này. Thông tin quan trọng nhất cần quan tâm là “information gain” là cách để chấm điểm từng câu hỏi. Và câu hỏi nào có “information gain” cao nhất, sẽ là câu hỏi tốt nhất.
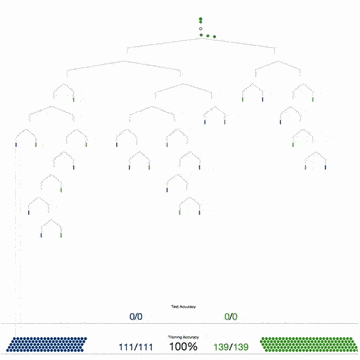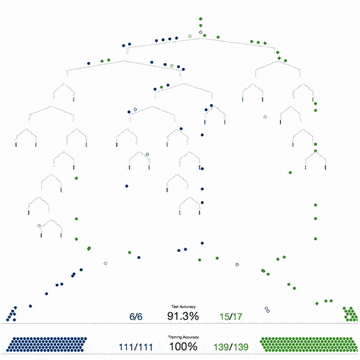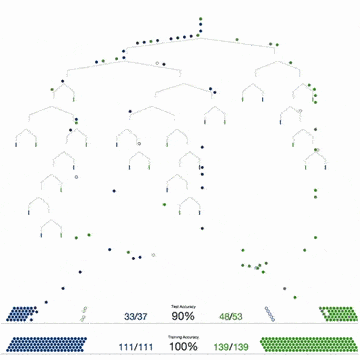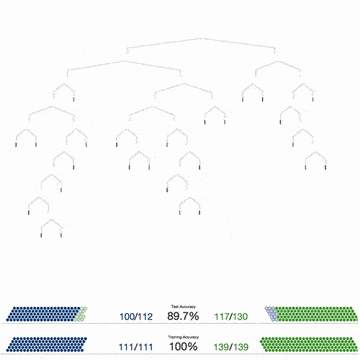
Biểu đồ dưới đây mô tả 4 bước để tạo ra 1 cây quyết định. Các bước này sẽ được lặp đi lặp lại cho tất cả các cây.

Một khi thuật toán đã xây dựng xong các cây quyết định, nó sẽ sử dụng chúng để trả lời các câu hỏi. Đối với Iris dataset, nó sẽ trả lời câu hỏi “Bông hoa kỳ bí thuộc loại nào?”
Nếu bạn để tâm đến các giải thích của tôi, có thể bạn sẽ thắc mắc: Tôi nói với bạn rằng, thuật toán đã tự tạo ra một vài cây quyết định, tuy nhiên tôi chỉ hướng dẫn bạn cách tạo và sử dụng duy nhất 1 cây quyết định thôi.
Cái hay của Random Forest là việc tạo ra mỗi cây quyết định có thể bỏ phiếu độc lập. Khi kết thúc việc bỏ phiếu, câu trả lời có lượng bỏ phiếu cao nhất, sẽ được chọn bởi Random Forest.
Tuy nhiên vẫn còn 1 vấn đề là: Nếu tất cả các cây quyết định đều được sử dụng cùng 1 cách, chúng sẽ giống nhau y hêt, do đó chúng luôn luôn có kết quả bỏ phiếu giống nhau. Do đó sẽ lại giống với việc sử dụng duy nhất 1 cây quyết định.
Con át chủ bài của Random Forest sẽ làm không ít người ngạc nhiên: Để chắc chắn rằng tất cả các cây quyết định là không giống nhau, Random Forest sẽ tự động thay đổi ngẫu nhiên đối tượng cần theo dõi. Nói một cách chính xác hơn, thuật toán sẽ xóa ngẫu nhiên 1 vài đối tượng, và nhân bản 1 vài đối tượng khác. Tổng quan thì việc thay đổi đối tượng kiểu này cũng không có gì khác biệt lawnsms, tuy nhiên chỉ cần vài chi tiết nhỏ thôi, cũng đã làm thay đổi toàn bộ kết quả của cây quyết định. Tiến trình này được gọi là “bootstrapping”.

Ngoài ra để đảm bảo rằng các cây quyết định có sự khác biệt, Random Forest sẽ ngẫu nhiên loại bỏ có mục đích một vài câu hỏi khi xây dựng cây quyết định. Trong trường hợp này, nếu câu hỏi tốt nhất không được kiểm tra, thì các câu hỏi khác sẽ được chọn để tạo ra cây. Tiến trình được gọi là “attribute sampling”.
Tôi cá rằng các bạn rất thắc mắc tại sao mọi người lại sử dụng thuật toán mà thay đổi ngẫu nhiên đối tượng theo dõi và loại bỏ ngẫu nhiên việc kiểm tra vài câu hỏi. Câu trả lời rất đơn giản: Có thể các mẫu thử mà chúng ta đang sử dụng chưa hoàn hảo. Ví dụ, có thể mẫu thử chỉ có thể chỉ ra rằng con mèo có lông ở đuôi. Trong trường hợp này những con mèo thuộc loài sphynx (mèo không lông), có thể được định nghĩa là con chuột. Tuy nhiên nếu câu hỏi về đuôi không được hỏi (bởi vì sự thay đổi ngẫu nhiên), thuật toán có thể sử dụng câu hỏi các câu hỏi khác (ví dụ: Con vật đó có kích thước như thế nào?), thì kết quả sẽ tốt hơn.
Trên đây là tất cả những gì tôi cần truyền đạt về Random Forest.
Qua 3 bài học, tôi đã giới thiệu rất chi tiết về sự Phân loại trong Machine Learning. Do đó khi nhắc đến khái niệm đánh dấu đói tượng theo dõi và các thuộc tính, các bạn sẽ có thể hình dung được hoạt động của chúng. Ngoài ra bạn cũng đã biết thêm về sự hoạt động của thuật toán k-nearest neighbor và Random Forest.
Theo dõi toàn bộ bài viết về Machine Learning tại: http://tech.3si.vn/category/machine-learning/