Mô hình song song
2014/11/09 bởi Tim Dettmers (http://timdettmers.com/2014/11/09/model-parallelism-deep-learning/)
Ở phần trước, tôi đã giải thích qua khái niệm về xử lý song song trên mô hình (MP-Model Parallelism) và dữ liệu (DP-Data Parallelism) cũng như phân tích làm thế nào để sử dụng DP hiệu quả trong học-sâu (Deep Learning). Ở bài viết này, tôi sẽ tập trung vào mô hình song song (MP).
XIn nhắc lại, mô hình xử lý song song là, khi bạn chia một mô hình thành từng phần cho các GPU và sử dụng cùng một dữ liệu cho từng mô hình; vì vậy mỗi GPU hoạt động trên một phần của mô hình chứ không phải là một phần của dữ liệu. Trong học-sâu, một cách để làm việc này bằng cách phân trọng số, ví dụ một ma trận 1000 x 1000 thì trọng số sẽ được phân chia thành các ma trận 1000 × 250 nếu bạn sử dụng 4 GPU.

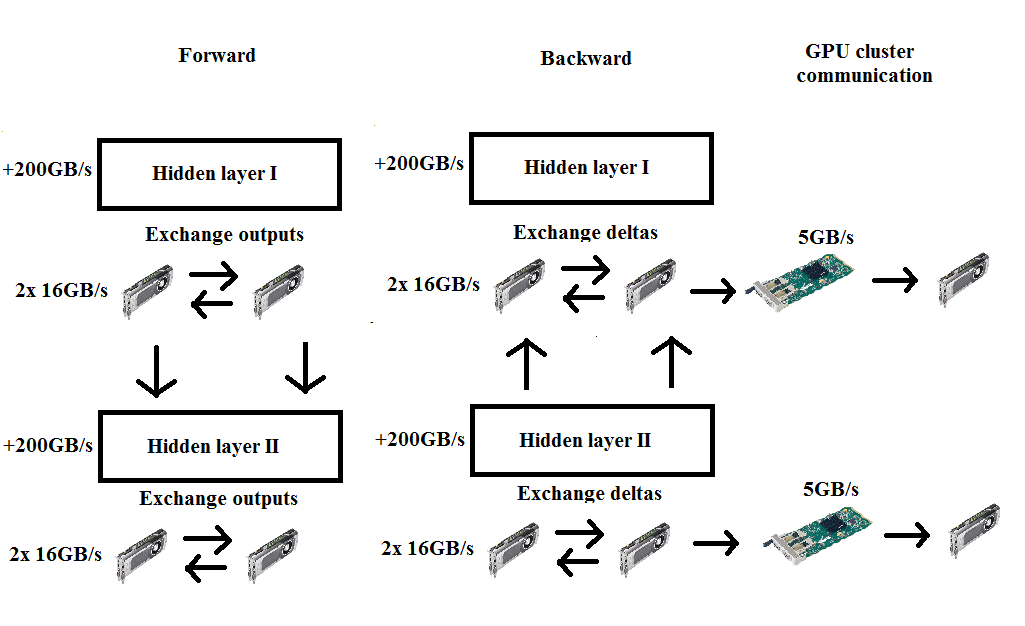
Sơ đồ MP. Đồng bộ hóa kết quả là cần thiết sau mỗi vòng tính tích vô hướng với ma trận trọng số cho cả hai chiều tiến và quy nạp.
Một lợi thế của phương pháp này nhận thấy ngay: Nếu chúng ta chia trọng số giữa các GPU chúng ta có thể chạy với mạng nơ-ron rất lớn dù rằng bộ nhớ của một GPU đơn lẻ không đủ dung lượng nạp trọng số vào. Ở phần trước, tôi cũng có nói rằng các mạng nơ-ron lớn như vậy là không cần thiết với đa số người. Tuy nhiên, đối với các tác vụ học-không-giám-sát (un-supervised learning) khủng hơn -trong tương lai thì sẽ khá phổ biến – mạng nơ-ron lớn lại rất cần thiết dùng để học được các đặc tả chi tiết nhất nhằm có được hành vi “thông minh”.
Làm thế nào để thuật toán chuyển tiến và quy nạp phân chia thành các ma trận như vậy được? Nếu nạp ma trận số học từng bước từng bước, ta sẽ thấy rõ ràng ngay:
Giả sử bắt đầu tìm kiếm tại A, B = C đó sẽ là tích ma trận trong trường hợp thông thường thuật toán tiến. Kích thước MP với 2 GPU, phân lô 128 và ma trận trọng số 1000 × 500 sẽ là:
Tiêu chuẩn: 128 × 1000 nhân 1000 × 500 = 128 × 500
Chia theo ma trận trọng số chiều dọc: 128 × 500 nhân 500 × 500 = 128 × 500 -> phép cộng ma trận
Chia theo ma trận trọng số chiều ngang: 128 × 1000 nhân 1000 × 250 = 128 × 250 -> phép chồng ma trận
Để tính toán sai số trong các lớp bên dưới, cần phải truyền các sai số tới được các lớp tiếp theo, hoặc nói theo cách toán học hơn, ta cần tính toán các giá trị delta bằng cách lấy tích vô hướng của các sai số ở lớp {i} trước với các trọng số kết nối lớp {j} tiếp theo , tức là :

Tiêu chuẩn: 128 × 500 nhân 500 × 1000 = 128 × 1000
Chia theo ma trận trọng số chiều dọc: 128 × 500 nhân 500 × 500 = 128 × 500 -> phép chồng ma trận
Chia theo ma trận trọng số chiều ngang: 128 × 250 nhân 250 × 1000 = 128 × 1000 -> phép cộng ma trận
Chúng ta thấy ở đây, cần phải đồng bộ hóa (cộng hoặc xếp chồng trọng số) sau mỗi kết quả tích vô hướng và bạn có thể nghĩ rằng như vậy sẽ chậm hơn so với xử lý dữ liệu song song DP ,vì DP đồng bộ hóa chỉ một lần. Nhưng có thể dễ dàng thấy rằng điều đó không phải đúng cho hầu hết các trường hợp, thử tính toán xem: Trong DP một khuynh độ của 1000 × 500 cần được truyền một lần/lớp cho 1000 × 500 lớp – tức là 500000 đơn vị; còn với MP chúng ta chỉ cần truyển một ma trận nhỏ cho tiến và quy nạp với tổng số 128000 hoặc 160000 đơn vị – dung lượng ít hơn gần 4 lần! Vì thế dù băng thông card mạng vẫn là nút cổ chai chính trong toàn bộ ứng dụng, nhưng sẽ ít bị ảnh hưởng hơn nhiều so với trong trường hợp DP.
Dĩ nhiên, tất cả chỉ là tương đối và phụ thuộc vào kiến trúc mạng. DP sẽ khá nhanh cho các mạng nhỏ và rất chậm cho các mạng lớn, MP thì ngược lại. Càng nhiều thông số, MP càng có lợi. Lợi thế càng thực sự rõ ràng khi mạng nơ-ron có trọng số vượt quá dung lượng một bộ nhớ GPU đơn.MP có thể xử lý việc mà thông thường sẽ cần đến hàng ngàn bộ vi xử lý CPU.
Tuy nhiên, nếu bạn chạy các mạng nhỏ, bộ nhớ GPU dư thừa và và vẫn còn năng lực xử lý (không phải tất cả các lõi đang chạy), thì dùng MP sẽ chậm. Không giống như DP, không có thủ thuật bạn có thể sử dụng để ẩn các thời gian giao tiếp cần thiết để đồng bộ hóa, điều này là bởi vì chúng ta chỉ có một phần thông tin cho toàn bộ phân lô. Với một phần thông tin này thì không thể tính toán các hoạt động trong lớp tiếp theo và do đó phải chờ đợi để hoàn thành đồng bộ hóa mới đi tiếp bước kế tiếp được.
Làm thế nào những lợi thế và bất cập có thể kết hợp được chỉ ra rõ ràng nhất bởi Alex Krizhevsky người đã chứng minh hiệu quả của việc sử dụng DP trong các lớp tính tích chập và MP trong các lớp dày đặc của một mạng nơ-ron tích chập.