Như ở phần HPC build 3, tôi đã thống nhất lựa chọn dòng GTX 780Ti, tên mã vi kiến trúc Kepler (Kepler Microarchitecture GK110B) với số nhân CUDA lớn nhất vào thời điểm đầu năm 2015, 2880 CUDA cores. Mãi sau này, nó bị soán ngôi bởi Titan X với 3072 CUDA cores.
Chuyện thì dài nhưng túm lại tại thời điểm dựng máy, tôi có thể lựa chọn 3 dòng GPU của Nvidia như sau: (Nvidia nhộn phết khi đặt mỗi tên dòng kiến trúc là tên các nhà khoa học lỗi lạc của thế giới)Fermi: GeForce 400, 500 series, ra đời khoảng năm 2010, lúc này CUDA mới thực sự được chú ý tới vì GPU thay vì chỉ làm nhiệm vụ hiện thị hình ảnh thì giờ có thể được sử dụng trong tính toán. Khẩu hiệu lúc này là Giải pháp tính toán hình ảnh cách mạng (The Revolutionary Visual Computing Solution) Chiếc card tôi có đại diện cho dòng này là con Quadro FX5600 1.5GB, băng thông 384-bit với 192 CUDA cores. Giá thành xuất xưởng siêu khủng $2,999. Giờ thì nó đang bị lỗi artifact, chập văn chờn, theo kinh nghiệm là phải cho vào lò nướng.
Kepler: Nvidia tuyên bố xanh rờn: Kepler là kiến trúc nhanh nhất, hiệu năng nhất thế giới cho HPC. (Kepler – The World’s Fastest, Most Efficient HPC Architecture). Đến nay, ngay cả khi đã có thế hệ mới thay thế, tuyên bố này phần nào vẫn đúng trong các dòng GPU của Nvidia sản xuất. Đại diện dòng này tôi sắm 4 chiếc card siêu độ cho dân OC EVGA GTX 780 Ti Classified, 3GB, băng thông 384-bit với 2880 CUDA cores. Giá xuất xưởng là $799. Tốn một mớ tiền x 4 vào đây. Và chúng sẽ là bạn đồng hành trải nghiệm qúa trình DL của tôi suốt thời gian ban đầu này.
Maxwell: Đây cũng là một kiến trúc được Nvidia quảng bá đổi mới nhưng thực ra, cá nhân tôi cho rằng mới mà không mới so với Kepler trước đây. Nó cũng không tạo ra cuộc cách mạng gì lớn giống như bước chuyển sang Kepler từ Fermi. Bản chất tập trung vào chỉnh sửa tối ưu tý chút đồng thời thiên về hỗ trợ kết xuất hình ảnh lớn cùng với xu thế độ phân giải siêu cao 4K hiện nay (VRAM nhiều lên hẳn). Vì thế khẩu hiệu đận này cũng đơn sơ: GPU tân tiến nhất qủa đất (The World’s Most Advance GPU). Đại diện cho dòng này tôi mua chiếc ASUS GTX 980 Strix, với 4GB, băng thông 256-bit với 2048 CUDA cores. Gía thành xuất xưởng là $599. GTX 980 được tôi lắp nâng cấp trên MacPro dành cho các tác vụ kiểm thử các vòng lặp tính toán (computing loop) đơn giản bên ngoài trong khi máy HPC kia bận rộn tính toán.
Chỉ với những thông điệp “ngầm” trên đủ thấy Kepler có vẻ mới chính là dòng kiến trúc chip chủ đạo mà Nvidia kỳ vọng tương đối lớn trong lĩnh vực điện toán HPC.
Trước khi xem xét cấu trúc phần cứng từng dòng GPU, chúng ta đều thấy trong điện toán song song của NVIDIA, CUDA là con số rất đáng quan tâm. Chúng ta hay đánh đồng CUDA với số nhân xử lý GPU có trong một con card. Ví dụ như con GTX 780 Ti mà tôi dùng có đến 2880 CUDA cores, tức là có thể chạy 2880 nhân cùng lúc. Điều này giúp đơn giản hoá việc so sánh sức mạnh và tiên liệu năng lực tính toán của card nhưng kỳ thực không hoàn toàn chính xác. CUDA bản chất là một platform và thư viện phần mềm trên C/C++ với các API đề phục vụ các nhà phát triển có thể lập trình xử lý song song thông qua truy xuất trực tiếp tới tập lệnh và các lõi tính toán của GPU. Khả năng này còn được gọi là GPGPU (General-Purposed GPU). Các lập trình viên, thông qua thư viện CUDA để có thể điều khiển GPU nhằm và các tác vụ tính toán thông thường như serial CPU. Trong tổng thể 1 PC, luồng xử lý dùng CUDA có thể tóm tắt như trong hình dưới đây: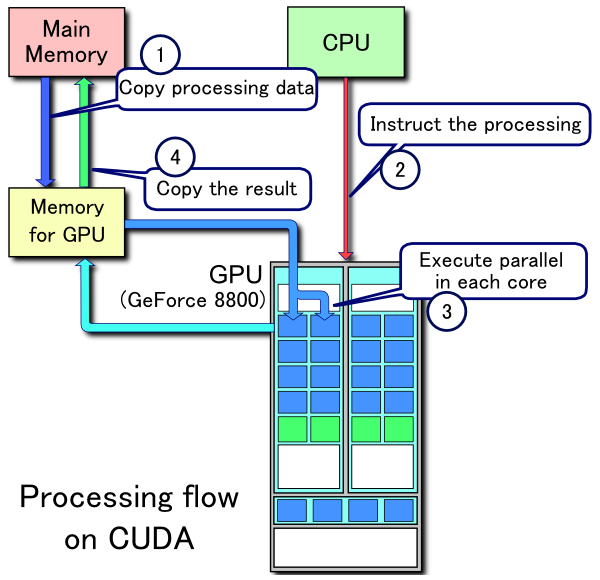
Với dòng Fermi, GPU thường có khoảng 3 tỷ chíp bán dẫn transistors, công nghệ 40nm là chính, tổ chức thành các tập xử lý dòng Streaming Multiprocessor gồm 32 CUDA mỗi tập. Về lý thuyết, khả năng tính toán SP của Fermi GPU (theo GFLOPS) là 2 (lệnh theo FMA mỗi chu kỳ, Fused Multiply-Add kiểu AxB+C) x số lượng nhân CUDA x tốc độ chip đổ bóng (in GHz). Còn về tính toán dấu chấm động FP64 thì khả năng giảm đi 1/2. (điều này đúng trên Tesla và Quadro chứ trên GTX, Nvidia làm thọt đi còn 1/8 thôi, quá láo). Đặc trưng của Fermi là cơ bản nhân CUDA nào cũng có khả năng thực hiện 2 phép tính SP32 hoặc 1 phép tính FP64 trong 1 xung nhịp clock. Vì vậy, hiệu năng sẽ giảm khi không cần tính toán đến như thế trên tất cả các cores và khiến cho lượng tiêu thụ điện dòng Fermi rất khủng, đồng thời, có thể đun nước sôi pha trà với lượng nhiệt của dòng card này. 
 Cũng với lý đó, Kepler ra đời sau đặt nặng hiệu năng tính toán và lượng năng lượng tiêu thụ hơn. Sản xuất với công nghệ 28nm, Con GK110 trong GTX 780 Ti có đến 7,1 tỷ chíp bán dẫn, gấp hơn 2 lần đời Fermi. Kepler ngoài các thế mạnh cũ thì cũng được tích hợp một loạt tính năng mới phục vụ cho điện toán song song như SMX (NeXt generation Streaming Multiprocessor), DP (Dynamic Parallelism), Hyper-Q MPI, GPUDirect… Có điều kiện tôi, sẽ đi sâu hơn về các tập kiến trúc mới này của Kepler riêng. Ở Kepler, CUDA Core vẫn có năng lực tính toán SP32 như trước, tức là 2 FMA mỗi chu kỳ nhưng không còn cõng phép tính FP64 mỗi nhân nữa mà thêm nhân tính toán FP64 riêng. Tỷ lệ tiêu chuẩn trên dòng cao cấp Titan Black, hay 780 Ti là 3:1 tức cứ 3 CUDA cores có 1 FP64(DP Unit màu cam). Ở các Kepler khác thì 24:1. Chính vì thế mà Kepler tiêu thụ điện lẫn toả nhiệt đã ít đi rất nhiều nếu so cùng năng lực tính toán ở dòng Fermi.
Cũng với lý đó, Kepler ra đời sau đặt nặng hiệu năng tính toán và lượng năng lượng tiêu thụ hơn. Sản xuất với công nghệ 28nm, Con GK110 trong GTX 780 Ti có đến 7,1 tỷ chíp bán dẫn, gấp hơn 2 lần đời Fermi. Kepler ngoài các thế mạnh cũ thì cũng được tích hợp một loạt tính năng mới phục vụ cho điện toán song song như SMX (NeXt generation Streaming Multiprocessor), DP (Dynamic Parallelism), Hyper-Q MPI, GPUDirect… Có điều kiện tôi, sẽ đi sâu hơn về các tập kiến trúc mới này của Kepler riêng. Ở Kepler, CUDA Core vẫn có năng lực tính toán SP32 như trước, tức là 2 FMA mỗi chu kỳ nhưng không còn cõng phép tính FP64 mỗi nhân nữa mà thêm nhân tính toán FP64 riêng. Tỷ lệ tiêu chuẩn trên dòng cao cấp Titan Black, hay 780 Ti là 3:1 tức cứ 3 CUDA cores có 1 FP64(DP Unit màu cam). Ở các Kepler khác thì 24:1. Chính vì thế mà Kepler tiêu thụ điện lẫn toả nhiệt đã ít đi rất nhiều nếu so cùng năng lực tính toán ở dòng Fermi.
Con 780 Ti của tôi có 2880 CUDA Cores, tức là có 2880/3=960 DP Unit dùng cho tính toán FP64, hiệu năng FP64 của nó sẽ là 960 GFLOPS.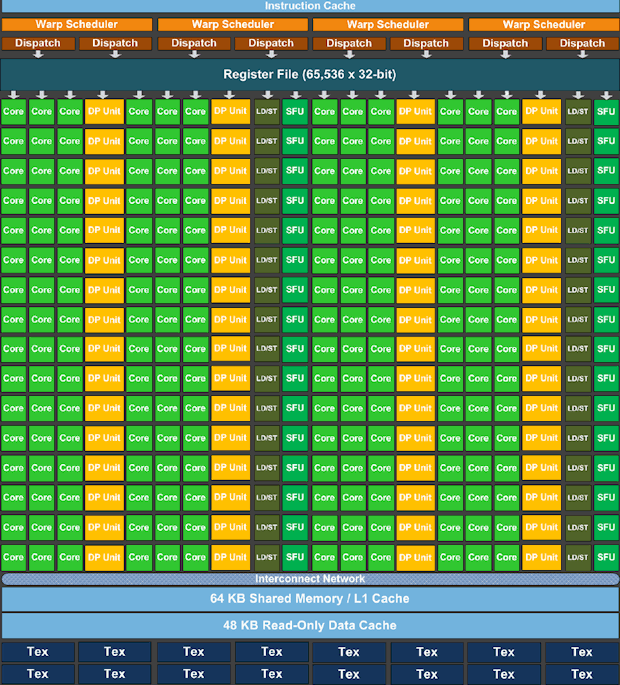
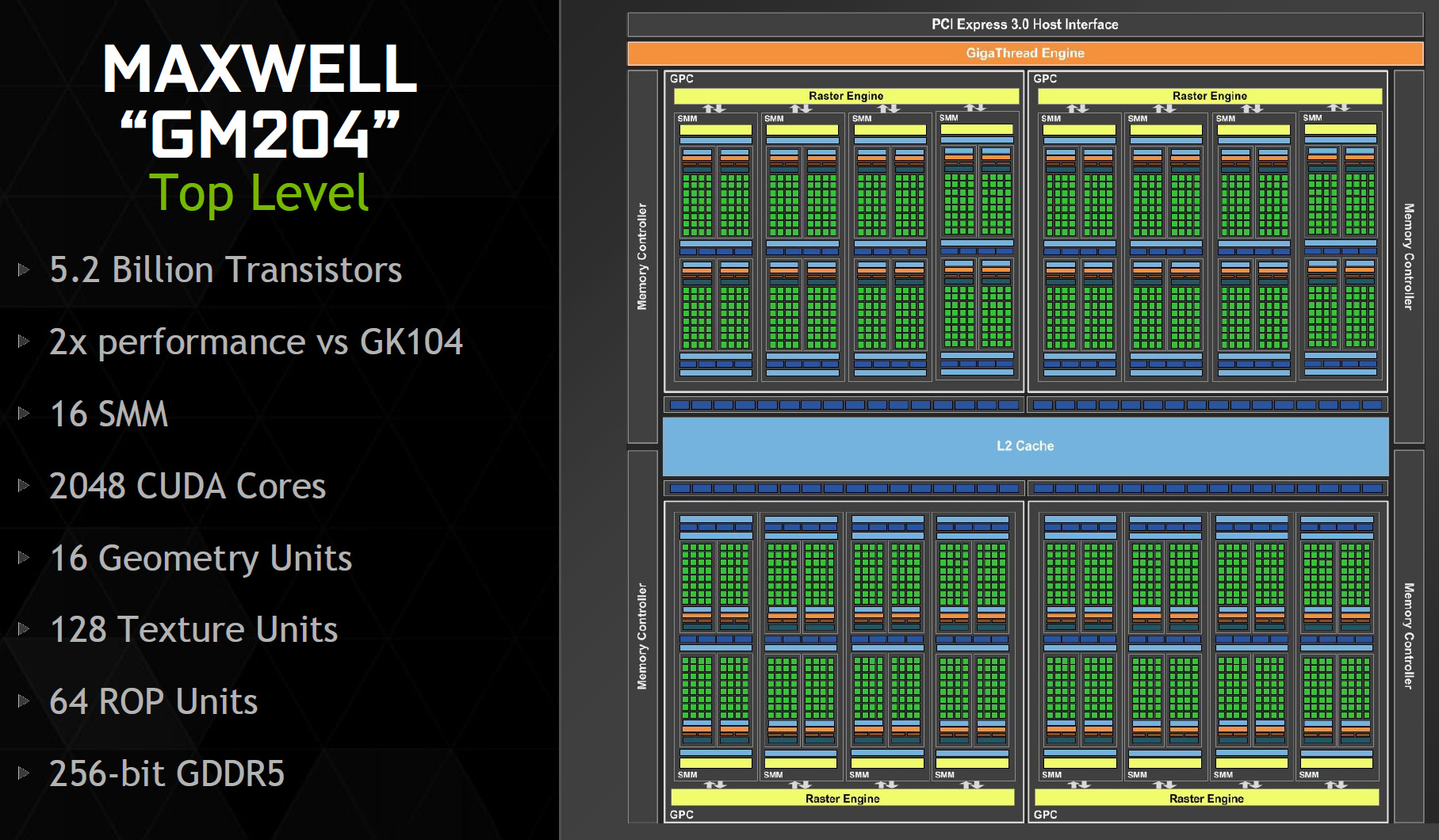
 Sang dòng chip hiện thời Maxwell, kiến trúc tương tự như Kepler nhưng NVIDIA bỏ hẳn luôn nhân tính toán FP64. Toàn bộ xử lý FP64 được đẩy sang 1 core khác là Texture Mapping Unit (TMU), tỉ lệ là CUDA/TMU là 32/1 Về năng lực SP trên CUDA vẫn tương tự Kepler và Fermi nhưng FP64 thì giảm tương đối, còn lại khoảng 1/32 khả năng SP32. Chính vì thế, năng lực FP64 được xem rất tồi và kém hơn hẳn so với Kepler. Số lượng bán dẫn cũng giảm xuống còn 5.2 tỷ transistors. Ví như con GTX 980 hàng đầu giờ chỉ có 128 TMU, tương đương với hiệu năng FP64 là 128 GFLOPS, chỉ bằng ~ 1/8 chú GTX 780 Ti của tôi. Được cái, thế này thì đỡ tốn điện đi nhiều đấy.
Sang dòng chip hiện thời Maxwell, kiến trúc tương tự như Kepler nhưng NVIDIA bỏ hẳn luôn nhân tính toán FP64. Toàn bộ xử lý FP64 được đẩy sang 1 core khác là Texture Mapping Unit (TMU), tỉ lệ là CUDA/TMU là 32/1 Về năng lực SP trên CUDA vẫn tương tự Kepler và Fermi nhưng FP64 thì giảm tương đối, còn lại khoảng 1/32 khả năng SP32. Chính vì thế, năng lực FP64 được xem rất tồi và kém hơn hẳn so với Kepler. Số lượng bán dẫn cũng giảm xuống còn 5.2 tỷ transistors. Ví như con GTX 980 hàng đầu giờ chỉ có 128 TMU, tương đương với hiệu năng FP64 là 128 GFLOPS, chỉ bằng ~ 1/8 chú GTX 780 Ti của tôi. Được cái, thế này thì đỡ tốn điện đi nhiều đấy.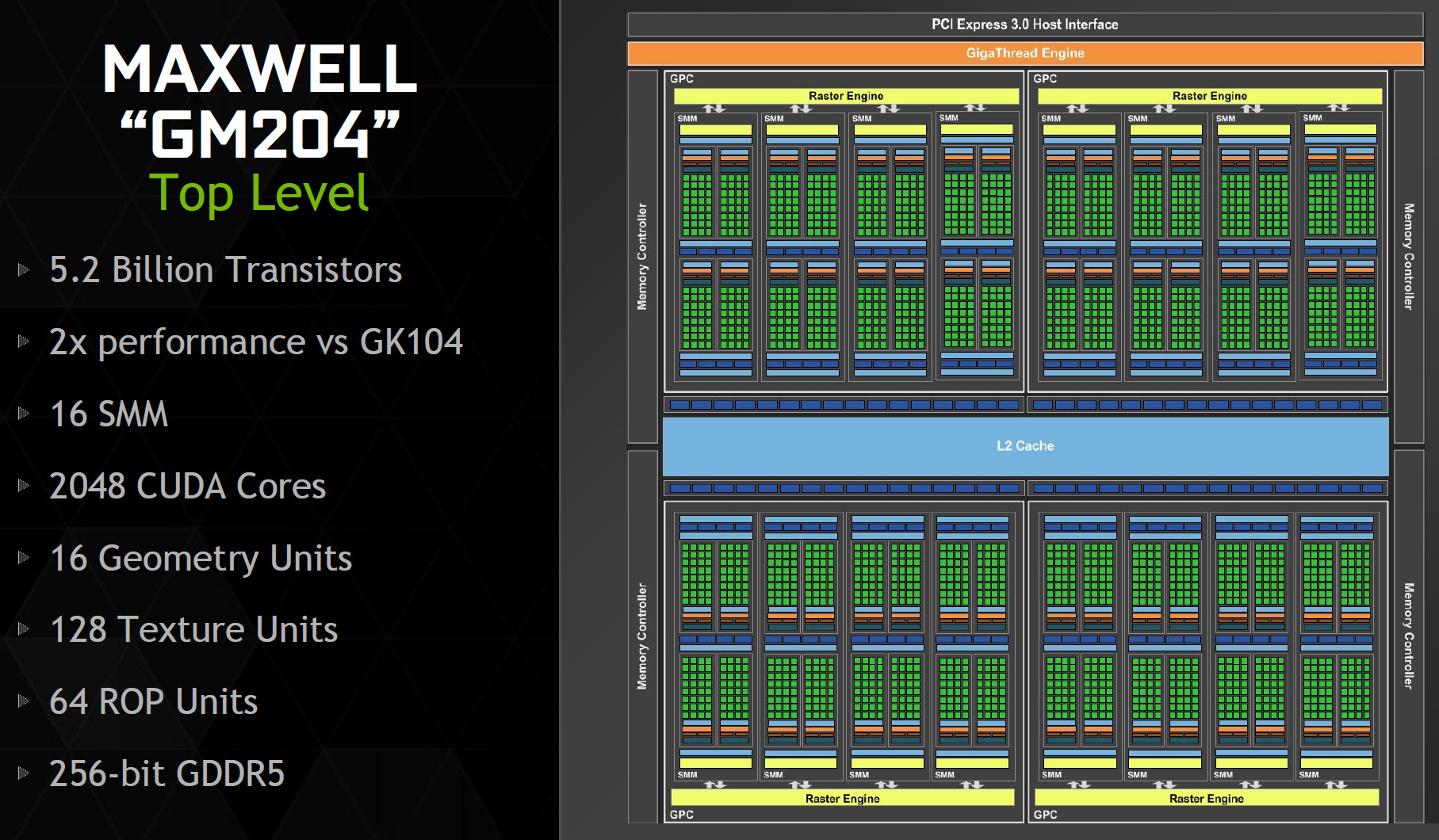
 Với 3 dòng trên, Maxwell sẽ là kiến trúc duy nhất không có dòng siêu hi-end Tesla tăng tốc tính toán mà chỉ dùng cho dạng Tesla Grid và vGPU (Virtual GPU: card đồ hoạ ảo). Chiếc GPU Nvidia Tesla khủng nhất hành tinh đến tận giờ là chiếc K80 (K thì rõ ràng là Kepler rồi nhá), với 2 GPU GK210, 2×2496 = 4992 CUDA cores và VRAM siêu khủng 24GB.
Với 3 dòng trên, Maxwell sẽ là kiến trúc duy nhất không có dòng siêu hi-end Tesla tăng tốc tính toán mà chỉ dùng cho dạng Tesla Grid và vGPU (Virtual GPU: card đồ hoạ ảo). Chiếc GPU Nvidia Tesla khủng nhất hành tinh đến tận giờ là chiếc K80 (K thì rõ ràng là Kepler rồi nhá), với 2 GPU GK210, 2×2496 = 4992 CUDA cores và VRAM siêu khủng 24GB.
Như vậy, cho đến giờ, dòng Kepler vẫn là dòng chủ đạo số 1 trong các hệ thống HPC. Chiếc siêu máy tính Titan, xếp hạng số 2 thế giới nhưng là số 1 trong nền tảng CUDA hiện giờ cũng dùng Kepler, với 2688 CUDA (cùng nhân GTX 780). Vì thế Kepler cũng là lựa chọn hàng đầu đa mục đích cho chiếc HPC của tôi. Như ở phần HPC build 3, các bạn cũng biết tôi đã chọn lắp 4 chiếc card GPU EVGA GTX 780 Ti. Đây là một trong những dòng đỉnh cao nhất của Kepler mà Nvidia sản xuất dành cho game thủ được EVGA chế tác riêng và đã OC Ready. Những thông số cơ bản dưới đây, đặc biệt được bôi đậm là nhưng số có ảnh hưởng lớn đến việc sử dụng GPGPU trong các HPC.
- Base Clock: 1020 MHZ (so với bản ref của Nvidia là 876 Mhz)
- Boost Clock: 1085 MHz (so với bản ref của Nvidia là 928 Mhz)
- Memory Clock: 7000 MHz Effective
- CUDA Cores: 2880
- Bus Type: PCI-E 3.0
- Memory Detail: 3072MB GDDR5 (dư dùng cho game nhưng thật tiếc, nếu kiếm dòng Titan Black dễ dàng hơn với 6GB thì sẽ thực sự ngon dùng cho neuron networks lớn)
- Memory Bit Width: 384 Bit
- Memory Speed: 0.28ns
- Memory Bandwidth: 336 GB/s
Trụ được đến đây, xin mời các bạn hãy thư giãn với một clip 20s khi tôi phải lắp lại nguồn để cấp đủ 8-pin x 2 vào mỗi con card của HPC.
Vậy trong tương lai, khi Nvidia đã hoàn toàn chú tâm và đầu tư mạnh mẽ bậc nhất vào phân hệ sức mạnh cho xử lý trí tuệ nhân tạo, AI, Deep Learning thì có gì sẽ thay đổi. Dù không phủ định, gaming đồ hoạ vi tính vẫn là thị trường bậc nhất nhưng những biến chuyển gần đây cho thấy Nvidia sẽ tiếp tục tạo được sự hợp lực cả hai hướng đi trên. NVIDIA đã công bố lộ trình trong tương lai gần năm 2016 sẽ ra mắt GPU Pascal (như một bước chuyển tiếp đến Volta 2018???) bổ sung sức mạnh cho các dòng hiện tại chủ yếu liên quan đến HPC, AI & DL.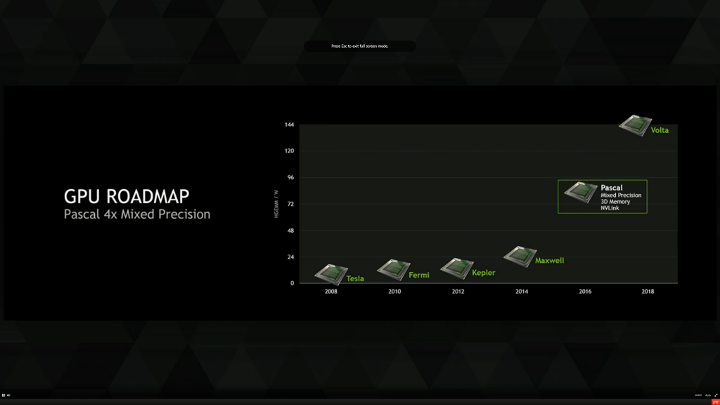
Pascal là cuộc cách mạng của Nvidia hướng tới điện toán cao cấp cho trí tuệ nhân tạo và các mạng thần kinh neuron network. Pascal có thể tóm lược ở 3 điểm:
- Tổ hợp toán cả 16 bit và 32 bit tạo nên sức mạnh tính toán gấp 4 lần Maxwell hiện tại.
- Công nghệ HBM (High Bandwidth Memory- Bộ nhớ băng thông cao) sẽ thay thế cho GDDR5 (ATI đã tiên phong đưa vào sử dụng trong dòng GPU Fury X năm qua). Lượng VRAM tăng tới 32 GB và cho băng thông 6x hiện tại với HBM (bản chất là chồng các chip nhớ lên nhau, nên còn gọi là 3D VRAM)
- Công nghệ truyền dữ liệu NVLINK giữa các GPU với nhau cho băng thông từ 80->200 GB/s, tức là nhanh gấp từ 5 đến 12 lần băng thông PCIe x 16 gen 3 hiện tại.
Với 3 cải tiến trên, sức mạnh tổng thể của card đồ hoạ thế hệ Pascal sẽ có bước nhảy vọt, gấp 10 lần so với kiến trúc Maxwell hiện tại. Thật nóng lòng đợi nhà “bác học” Pascal nhưng nếu thế đến tay người dùng chắc phải gần hơn 1 năm nữa nhưng nếu không thật vội vàng và cấp thiết như tôi thì hãy chờ đợi một chút cũng đáng. Nếu sẵn tiền và chỉ cần để học hành tý chút thì hãy dòn tiền quất 1 con Titan X 12GB là đủ để tiếp tục chờ đợi.