I. Introduction
There are many modern object detectors such as Faster R-CNN, R-FCN, Multibox, SSD and YOLO, which are good enough to be deployed in consumer products (e.g. Google Photos, Pinterest Visual Search) and some have been shown to be fast enough to be run on mobile devices. Because of its varieties, it sometimes makes us hard to choose the one that fit to our applications. This blog will cover basic information about these models and making comparison among them to help you make decisions more easily.
Looking at the table below, you can see there are many other models available.

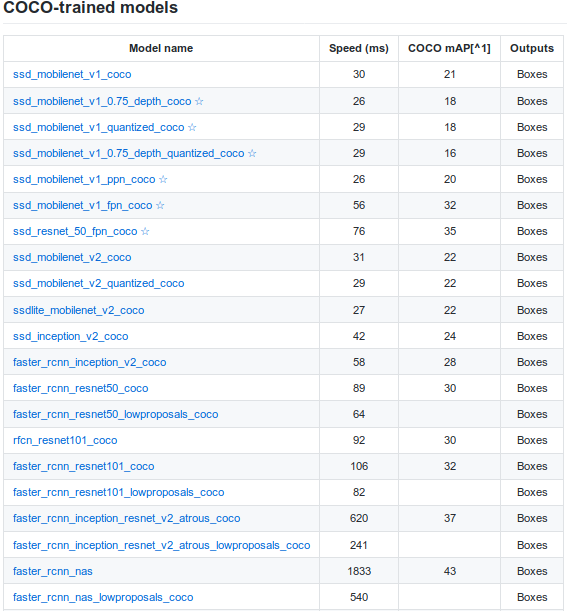
Table 1: Deep Learning models trained on COCO dataset
Note that model speed is reported as the running time in ms per 600×600 image (including all pre and post-processing) performed using an Nvidia GeForce GTX TITAN X card. Note that desktop GPU timing does not always reflect mobile run time. For example, mobilenet v2 is faster on mobile devices that mobilenet v1, but is slightly slower on desktop GPU.
Mean Average Precision (mAP) is considered as standard accuracy metrics of these models that tell us how well performance of the model does. But it does not tell the entire story, since for real deployments of computer vision systems, running time and memory usage are also critical. For example, mobile devices often require a small memory footprint, and self driving car require real time performance. Server-side production systems, like those used in Google, Facebook or Snapchat, have more leeway to optimize for accuracy, but are still subject to throughout constraints. While the methods that win competitions, such as the COCO challenge are optimized for accuracy, they often rely on model ensembling and multicrop methods which are too slow for practical usage.
One of the biggest practical considerations is the speed and accuracy tradeoff. Researchers have developed a wide variety of architectures to match the different use cases that applications might encounter in the real world. For examples, perhaps your models is supposed to run on a compute-limited mobile phone, so you might be looking for a MobileNet architecture that’s lightweight and fast. Otherwise, if you’re not compute constrained but want to have the best accuracy, you can go with whatever the-state-of-the-art promises you the best accuracy, regardless of how slow or big the model is.
Generally models that take longer to compute perform better. However these models also have a number of subtle differences (such as performance on small objects). Their strengths and weakness can be presented more detail in the following section.
II. Compare and get results
This section will present a unified implementation of the three recent architecture: SSD, Faster R-CNN and R-FCN system, which trace out the speed/accuracy trade-off curve created by using alternative feature extractors and varying other critical parameters such as image size.
1. Architectural Configuration
To make comparisons among these models, they created a detection platform in Tensorflow and have recreated training pipelines for SSD, Faster R-CNN and R-FCN on this platform. Having a unified framework has allowed us to easily swap feature extractor architectures, loss functions and having it in Tensorflow allows for easy portability to diverse platforms for deployment.
– Feature extractors technique: VGG-16, Resnet-101, Inception v2, Inception v3, Inception Resnet (v2), MobileNet. We evaluate all combinations of meta-architectures and feature extractors, most of which are novel. Notably, Inception networks have never been used in Faster R-CNN frameworks and until recently were not open sourced.
– Input size configuration: Faster R-CNN and R-FCN models are trained on images scaled to M pixels on the shorter edge whereas in SSD, images are always resized to a fixed shape MxM. They have trained high and low-resolution versions of each model. In the “high-resolution” setting, set M=600 and M=300 in the remained setting. We can see that SSD method processes fewer pixels on average that a Faster R-CNN or R-FCN model with all other variables held constant.
– Benchmarking procedure: To time their models, they use a machine with 32GB RAM, Intel Xeon E5-1650 v2 processor and an Nvidia GeForce GTX Titan X GPU card. Timings are reported on GPU for a batch size of one. The images used for timining are resized so that the smallest size is at least k and then cropped to kxk where k is either 300 or 600 based on the model. We average the timings over 500 images.
2. Results
For each model configuration, they measure timings on GPU, memory demand and number of parameters as described below. Each (architecture, feature extractor) pair can correspond to multiple points on this plot due to changing input sizes, stride…

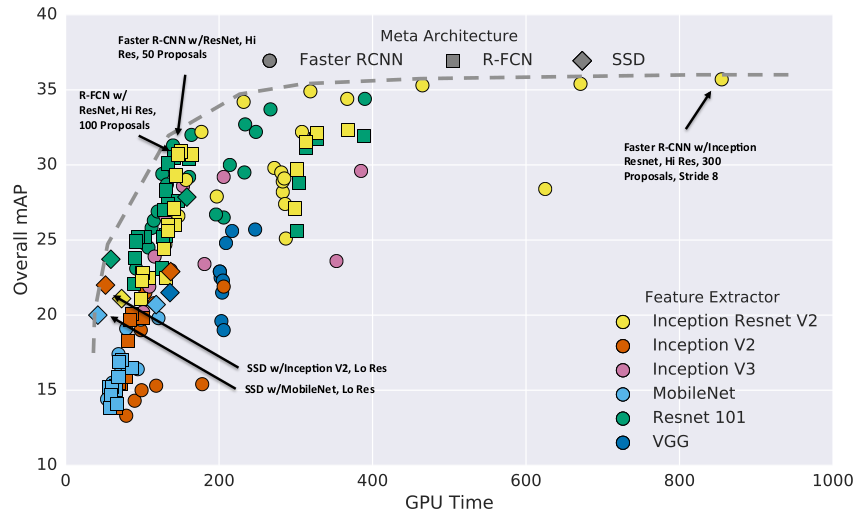
- Accuracy vs time
As you can see from figure 1, running time per image ranges from tens of milliseconds to almost 1 second. Generally we observe that R-FCN and SSD models are faster on average while Faster R-CNN tends to lead to slower but more accurate models, requiring at least 100 ms per image.
- Critical points
– Fastest: SSD w/MobileNet. We see that SSD models with Inception v2 and MobileNet feature extractors are most accurate of the fastest models. Note that if we ignore post-processing costs, Mobilenet seems to be roughly twice as fast as Inception v2 while being slightly worse in accuracy.
– Middle points: R-FCN w/Resnet or Faster R-CNN w/Resnet, 50 proposals. R-FCN models using Residual network feature extractors which seem to strike the best balance between speed and accuracy among our model configurations. Faster R-CNN w/Resnet models can attain similar speed if we limit the number of proposals to 50.
– Most accurate: Faster R-CNN w/Inception Resnet. Faster R-CNN with dens output Inception Resnet models attain the best possible accuracy on our models, to our knowledge, the state-of-the-art single model performance. However, these models are slow, requiring nearly a second of processing time.
- Effect of feature extractor
Intuitively, stronger performance on classification should be positively correlated with stronger performance on COCO detection. The relationship between overall mAP of difference models and the Top-1 Imagenet classification accuracy attained by the pretrained feature extractor used to initialize each model is shown in Figure 2. However, this correlation appears to only be significant for Faster R-CNN and R-FCN while the performance of SSD appears to be less reliant on its feature extractor’s classification accuracy.

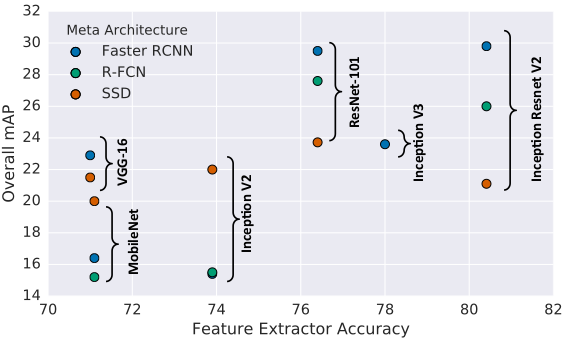
Figure 2: Accuracy of detector (mAP on COCO) vs accuracy of feature extractor
- Effect of object size
Figure 3 shows performance for different models on different sizes of objects. Not surprisingly, all methods do much better on large objects. We also see that even though SSD models typically have poor performance on small objects, they are competitive with Faster R-CNN and R-FCN on large objects, even outperforming these architectures for the faster and more lightweight feature extractors.

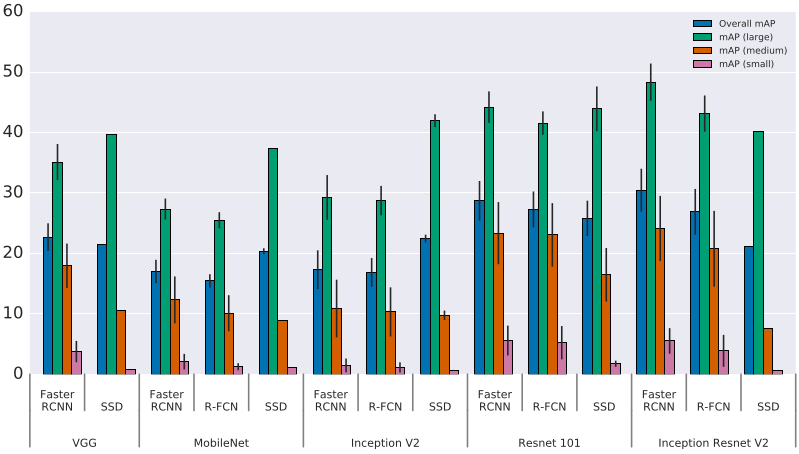
Figure 3: Accuracy stratified by object size, architecture and feature extractor
- Effect of image size
They observe that decreasing resolution by a factor of two in both dimensions consistently lowers accuracy (by 15.88% on average) but also reduces inference time by a relative factor of 27.4% on average. One reason for this effect is that high resolution inputs allow for small objects to be resolved. Figure 4 compares detector performance on large objects against that on small objects, confirms that high resolution models lead to significantly better mAP results on small objects (by a factor of 2 in many cases) and somewhat better mAP results on large objects as well. We also see that strong performance on small objects implies strong performance on large objects in our models.

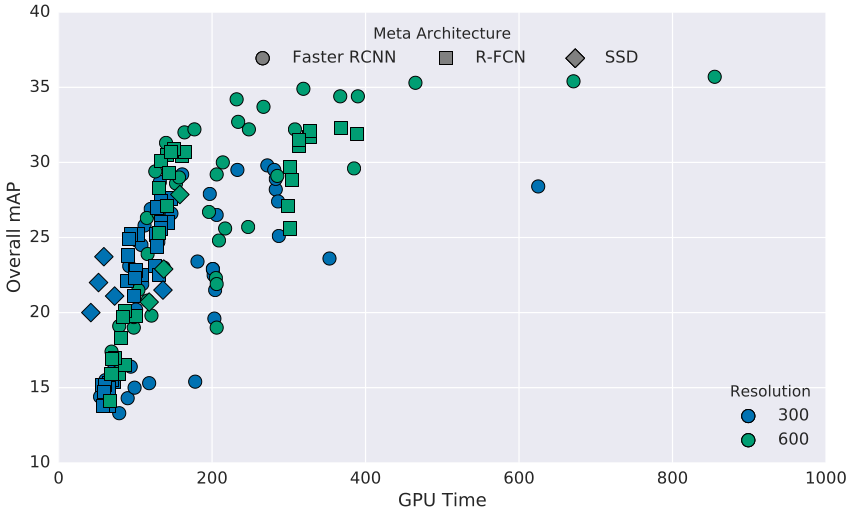
Figure 4: Effect of image resolution
- Memory analysis
For memory benchmark, they measure total usage rather than peak usage. Figure 5a, 5b plot memory usage against GPU and CPU times. Overall, we observe high correlation with running time with larger and more powerful feature extractors requiring much more memory. Figure 6 plots some of the same information in more detail. As with speed, Mobilenet is again the cheapest, requiring less than 1Gb (total) memory in almost all settings.

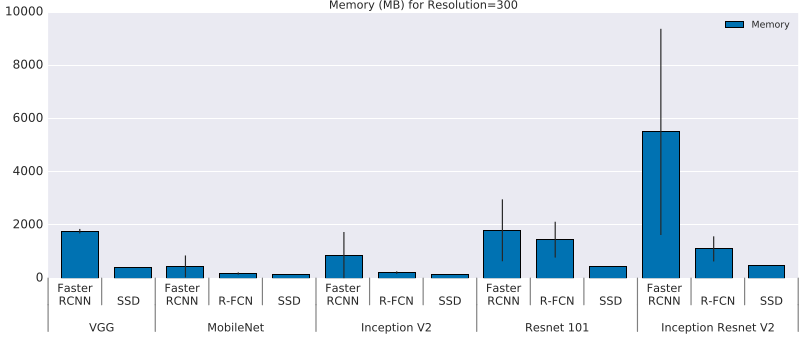
Figure 5: Memory (Mb) usage for each model

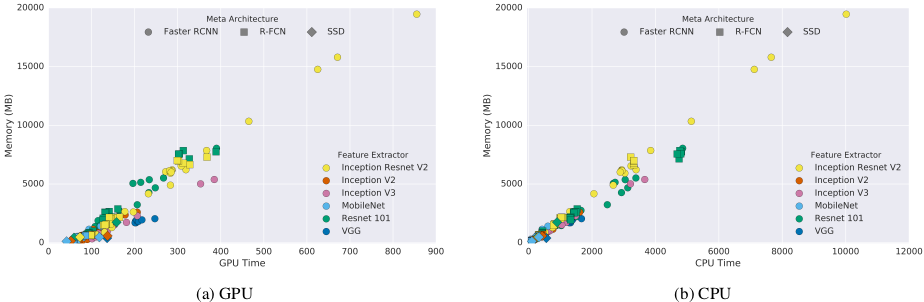
Figure 6: Memory (Mb) vs time
III. YOLO Object Detector
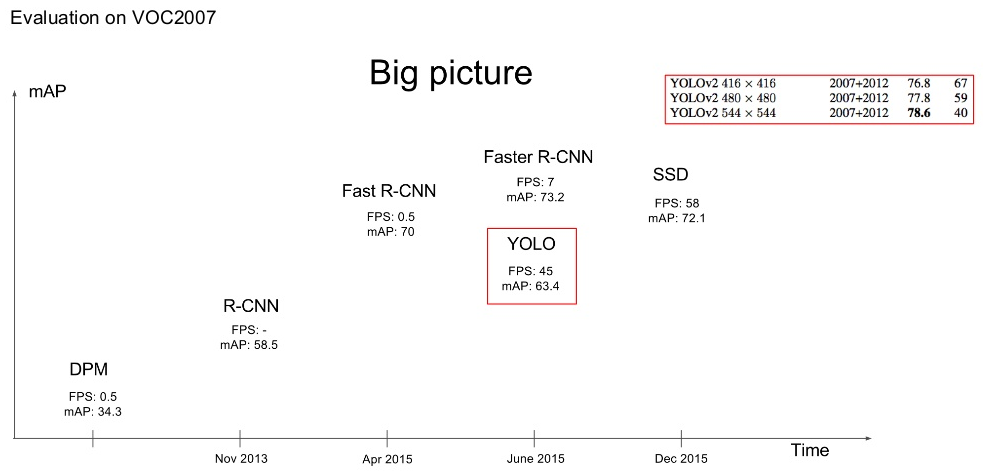
YOLO is a new approach to object detection and it is extremely fast. In term of accuracy, it’s only slightly worse performance than Faster R-CNN. YOLO model processes images in real-time at 45 frames per second. A smaller version of the network, Fast YOLO, processes an astounding 155 frames per second while still achieving double the mAP of other real-time detectors. Compared to state-of-the-art detection systems, YOLO makes more localization errors of bounding boxes – treats error the same for small vs large boxes. It also performs worse with groups of small objects. You can see the big picture of object detectors when YOLO appears.

After YOLO, they improved to YOLO v2, YOLO v3 with really good performance of both accuracy and time. The compare between YOLO v2 and others object detectors is presented in figure 8, 9 and it could be found in the github. Their findings show that Faster R-CNN Inception Resnet v2 obtains the bast mAP while R-FCN Resnet 101 strikes the best trade-off between accuracy and execution time. YOLO v2 and SSD Mobilenet merit a special mention, in that the former achieves competitive accuracy results and is the second fastest detector, while the latter is the fastest and the lightest model in terms of memory consumption, making it an optimal choice for deployment in mobile and embedded devices.

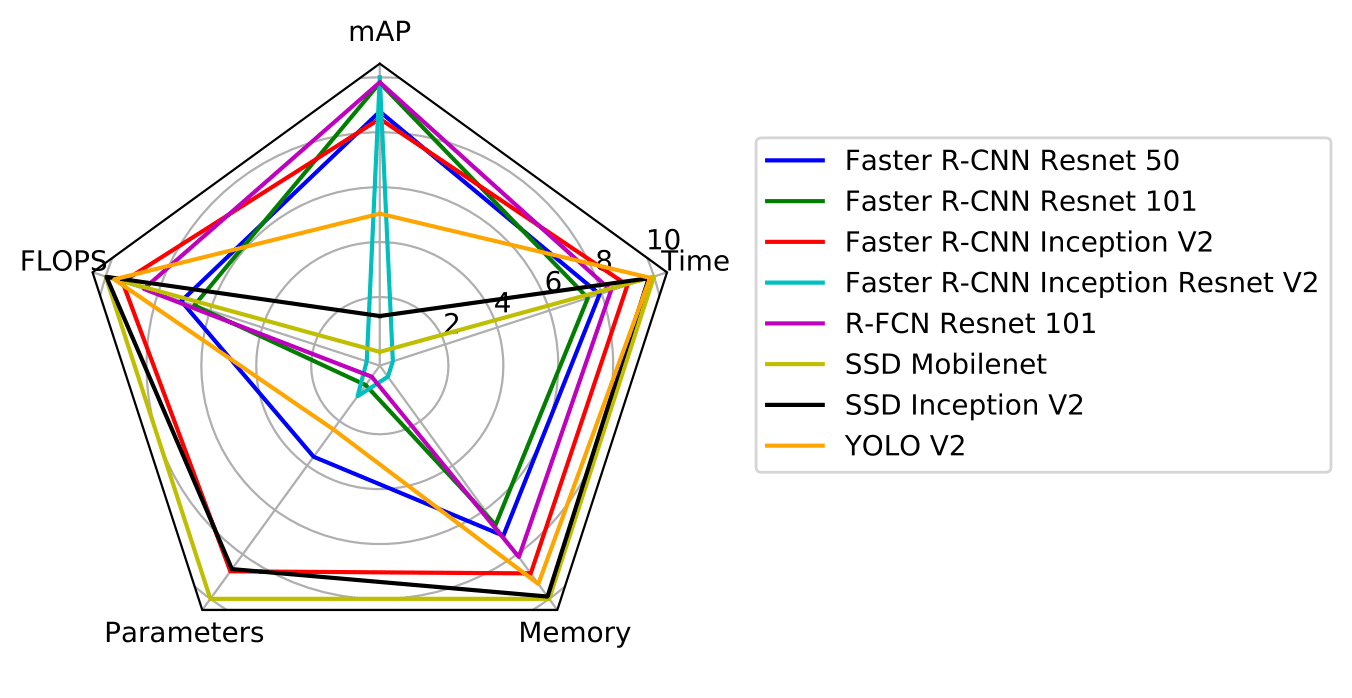
Figure 8: Comparison between YOLOv2 and others object detectors

Figure 9: Comparison between YOLOv2 and others object detectors in term of image size

IV. State-of-the-art detection on COCO
After reading the two above sections, you might have some questions on improving the performance of these object detectors or how to build a state-of-the-art model?
This section will present the technique for improving the performance (mainly on accuracy metric) of the object detector. This information is taken from a paper that is published in 2018. They ensembled some of their models to achieve the state of the art performance on the 2016 COCO object detection challenge. Their model attains 41.3% mAP@[.5, .95] on the COCO data test set and is an ensemble of five Faster R-CNN models based on Resnet and Inception Resnet feature extractors with varying output stride configurations, retrained using variations on the loss functions and different random orderings of the training data. You can find out more detailed information about this technique in the paper cited above.
V. Conclusion
We have performed an experimental comparison of some of the main aspects that influence the speed and accuracy of modern object detectors. For application requires lightweight and fast architecture such as mobile applications, SSD w/ Mobilenets is the best candidate. If you care much about the accuracy of your model, Faster R-CNN w/ Inception Resnet could be more suitable. And you also can find many “middle” architectures like R-FCN w/ Resnet that balance among other parameters such as memory by the above analysis.
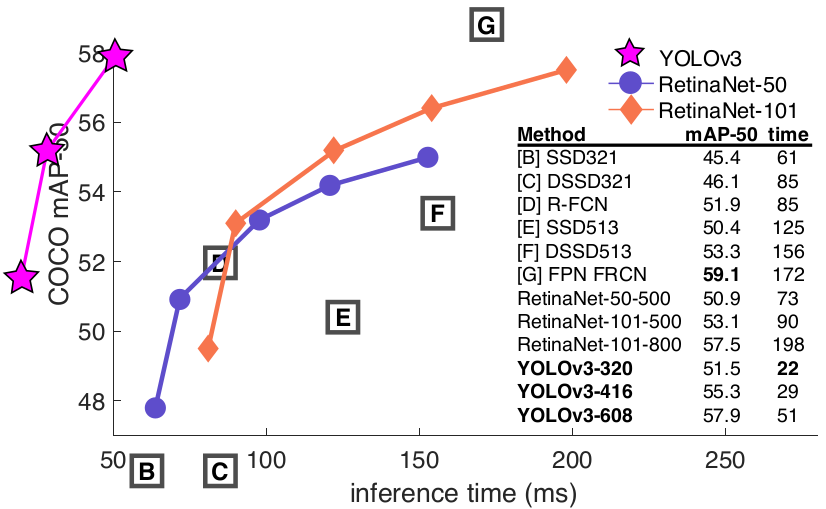
The latest version of YOLO (YOLOv3) is fast and accuracy. It’s really helpful in real-time applications. It seems to be the best choice for many applications now but the limitation of document support sometimes makes us less confident to select this one.