I’m writing this tech blog to give you some information about NLP project using FastText pretrained model and do some works to improve its performance in terms of accuracy.
I. NLP project
A NLP project can be processed as common process of Machine Learning project as in the following steps.
Step 1: Problem analysis
In this step, we should show the input, output and relation between them (if available) to clarify our goal or solutions. We also provide kind of problem, evaluative metrics… to make our problems more clearly.
Step 2: Get/crawl Data and pre-processing
To guarantee success of a Machine Learning project, we need much data that might be gotten from many sources. The more data we have, the better performance we get.
After we get the data, we should take pre-processing steps to make our data more “formally” that each data points have the same format.
Step 3: Choose Model and Training Data
We could choose an available pre-trained Deep Learning model or using self-developed model. There are many pre-trained models for object detection problems. But with NLP problems, the number of choice is much smaller. We have two outstanding platform for text processing is FastText of Facebook and (Fast)BERT of Google. The introduction to FastText could be found in the following section while (Fast)BERT study is out of this tech blog.
Step 4: Deploy to Production
After training, we do testing to make sure that our model is working well in localhost. Then we could deploy it on Web/App platform that others can access and experience our product.
II. FastText pre-trained model
1. Introduction
FastText is an open-source, free, lightweight library that allows users to learn text representations and text classifiers created by Facebook’s AI Research (FAIR) lab. The model allows to create an unsupervised learning or supervised learning algorithm for obtaining vector representations for words and available for 294 languages.
You can find more information from here and for installation from this website.
2. Characteristics of FastText model
FastText support many procedures such as train, predict, return probability, quantize… that you could find from the website.
a. Text classification
$./fasttext supervised -input train.txt -output model
Once the model was trained, you can evaluate it by computing the precision and recall at k (P@k and R@k) on a test set using:
$ ./fasttext test model.bin test.txt 1
b. Quantization
In order to create a .ftz file with a smaller memory footprint:
$ ./fasttext quantize -output model
You can test with this model using:
$ ./fasttext test model.ftz test.txt
c. Making FastText model better
There are some ways to making FastText model better. The model obtained by running FastText with the default arguments is pretty bad at classifying new questions.
– Preprocessing the data: if we observe that some words contain uppercase letter or punctuation, applying some simple pre-processing like normalization could improve the performance of our model.
– Hyperparameters tunning: Depending on the data, these default parameters may not be optimal. There are some key parameters for word vectors as below. This method will be studied in more detail in the next section.
The most important parameters of the model are its dimension and the range of size for the subwords. The dimension (dim) controls the size of the vectors, the larger they are the more information they can capture but requires more data to be learned. But, if they are too large, they are harder and slower to train. By default, they use 100 dimensions, but any value in the 100-300 range is as popular. The subwords are all the substrings contained in a word between the minimum size (minn) and the maximal size (maxn). By default, they take all the subword between 3 and 6 characters, but other range could be more appropriate to different langues.
Depending on the quantity of data you have, you may want to change the parameters of the training. The epoch parameter controls how many time will loop over your data. By default, we loop over the data 5 times. If your dataset is extremely massive, you may want to loop over it less often. Another important parameter is the learning rate (-lr). The higher learning rate is, the faster the model converge to a solution but at the risk of overfiting to the dataset. The default value is 0.05 which is good compromise. If you want to play with it we suggest to stay in the range of [0.01 1].
Word n-grams: we can improve the performance of a model by using word bigrams, instead of just unigrams.
What is Bigram? A ‘unigram’ refers to a single undiving unit, or token, usually used as an input to a model. For example, a unigram can be a word or a letter depending on the model. In fastText, they work at the word level and thus unigrams are words. Similarly we denote by ‘bigram’ the concatenation of 2 consecutive tokens or words. We often talk about n-gram to refer to the concatenation any n consecutive tokens.
For example, in the sentence, ‘I am a ML engineer’, the unigrams are ‘I’, ‘am’, ‘a’, ‘ML’ and ‘engineer’. The bigrams are: ‘I am’, ‘am a’, ‘a ML’ and ‘ML engineer’.
This is FastText’s parameters recommendation:
+ epoch in range [5 50];
+ lr in range [0.1 1];
+ wordNgrams in range [1 5];
+ dim in range [100 300].
3. Hyperparameters tunning
An important process for improving our model’s performance (for example: accuracy and/or speed). In our project, we care more about accuracy and try to do hyperparameters tunning for improving it.
There are some hyperparameters such as number of epoch, learning rate, wordNgrams and dim that could be used for tunning.
a. Evaluate the data/models
I’m trying to use different models to see the affect of data (words/labels) to the accuracy. I have used the configuration as “epoch=200, lr=0.9, wordNgrams=4, dim=300”.
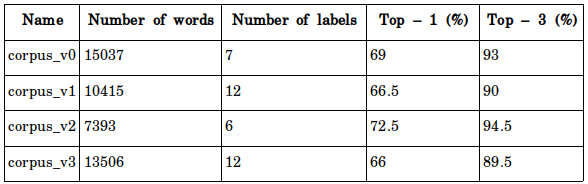
{kind=link}
From this table, we can see that the accuracy is proportional to the number of words and inversely proportional to the number of labels. So if we divide to fewer fields such as from 5 to 6 fields, I think our goal (Top-1 accuracy > 80%) is more reachable.
b. Evaluate the hyperparameters
We can assume problem with fixed parameters “wordNgrams = 4”, “dim = 300”. We can evaluate each hyperparameter separately because of its independence. I will run testing on the corpus_v2 dataset.
- The first train configuration
From FastText example: “epoch=25, lr=1, wordNgrams=2, dim=300”. We get the results of accuracy as:
Top-1 A = 72.5 %
We get the same result when run with “wordNgrams = 4”.
- Evaluate the learning rate (lr)
I tried some different value of lr and receive the results as follows:
+ Lr = 0.25, Top-1 A = 66.5 %
+ Lr = 0.5, Top-1 A = 70.6 %
+ Lr = 0.75, Top-1 A = 72.5 %
+ Lr = 1, Top-1 A = 73.5 %
Now I will run multiple times to find the optimal value (multiple training and save the points).
The new configuration for saving time: do not compress the model (although this will reduce the loss of training and reduce top-1 A). When I ran the simulation many times, I realized that it might be different among iterations or it’s not stable. My results are as follows:
Fisrt run,
Argmax = 17 (corresponding to lr = 1.7)
Max accuracy = 0.7412 corresponding to 74.12%
Second run,
Argmax = 19 (lr = 1.9)
Max accuracy = 0.7412 (74.12%)
Third run,
Argmax = 19 (lr = 1.9)
Max accuracy = 0.7412 (74.12%)
The effect of learning rate to accuracy is as in the following figure. We can see that the smaller learning rate is, the more stable the accuracy is. Moreover, the accuracy reach to the highest when Learning rate = 2. So we could choose the optimal value of learning rate is lr=2.

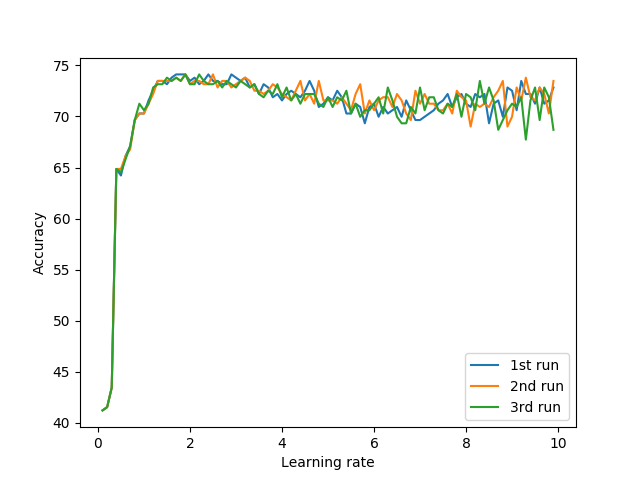
Figure 1: Learning rate vs. Top-1 Accuracy
- Evaluate the epoch
I ran my simulation with the configuration is as above: lr = 2, wordNgrams = 4, dim = 300. Then I got the results as follows:
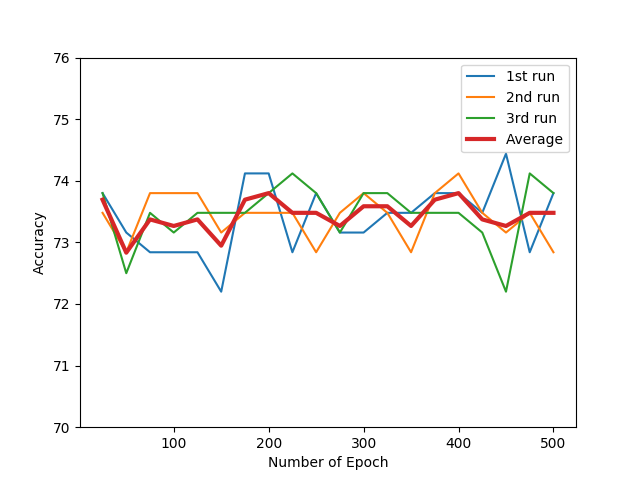
Figure 2: Accuracy vs. Number of Epoch
We could see that the accuracy is fluctuated as the number of epoch increases. The average accuracy reaches to the highest at the points: epoch=200 and epoch = 400. The more epochs cause our model tend to over-fitting. So I will choose the optimal value for Num of Epoch is epoch = 200.
With epoch = 200, lr = 2, wordNgrams = 4, dim = 300, I rerun simulations with different models and get the following results.
{kind=link}
Overall, our model has just been improved slightly. The size of data set also impacts the effective of improvements. So it’s hopeful that our model will be improved as we acquire more and more data in the future.
There may be a note that someone will think I should run much more iterations to conclude something, especially with epoch. But I think it’s not the same for any run but the difference among these runs is not much. So I think my simulation can be interrupted after some iterations.
3rd, June 2019: I have updated my result with some new data from Hue into the above table.
I hope this blog could give u some useful information about how to start and build a NLP project using FastText pretrained model. It should be noted that you could use many models that differ with FastText.