Phần 1: Dữ liệu song song – Data Parallelism
Viết 2014/10/09 bởi Tim Dettmers (http://timdettmers.com/2014/10/09/deep-learning-data-parallelism/)
Trong bài viết trước, tôi đã chỉ ra những gì cần chú ý khi bạn muốn xây dựng một cụm xử lý với nhiều GPU. Quan trọng nhất, bạn sẽ cần một kết nối mạng nhanh giữa các máy chủ và dùng thư viện MPI trong chương trình sẽ giúp đơn giản hóa vượt trội so với sử dụng các tùy chọn sẵn có của CUDA.
Ở bài viết này tôi sẽ giải thích làm thế nào để triển khai thuật toán xử lý song song cho mạng nơ-ron với một cụm GPU theo những cách khác nhau cùng với những lợi thế và bất cập của các thuật toán đó. Có hai hướng triển khai thuật toán khác nhau là xử lý dữ liệu song song (Data Parallelism- DP) hay xử lý mô hình song song (Model Parallelism -MP). Ở bài viết này tôi sẽ tập trung vào DP.
Vậy, hai hướng tiếp cận trên là gì? DP có nghĩa là bạn sử dụng cùng một mô hình giống nhau trên mỗi nhánh xử lý (thread), nhưng cấp cho các nhánh với từng phần khác nhau của cùng một bộ dữ liệu; còn MP thì sử dụng cùng một bộ dữ liệu cho mỗi nhánh, nhưng chia nhỏ mô hình thành các phần xử lý trên các nhánh khác nhau.
Đối với các mạng nơ-ron, điều trên có nghĩa DP sử dụng các trọng số giống nhau và mỗi nhánh xử lý các phân lô khác nhau; sau đó khuynh độ (gradient) cần phải được đồng bộ theo cách trung bình hóa, sau mỗi lần xử lý xong một phân lô.
MP thì chia trọng số của mạng đều ra cho các nhánh xử lý và tất cả các nhánh cùng xử lý trên cùng một phân lô; ở đây kết quả tạo được sau mỗi lớp xử lý cần phải được đồng bộ, theo cách xếp chồng lên nhau, để cung cấp đầu vào cho các lớp xử lý tiếp theo.
Mỗi phương pháp có ưu điểm và nhược điểm của nó, thay đổi theo kiến trúc xử lý. Trước tiên, chúng ta cùng xem xét DP (xử lý dữ liệu song song) với những yếu điểm nghẽn cổ chai của nó, còn trong bài viết tiếp theo, tôi sẽ xét đến xử lý kiểu MP (xử lý mô hình song song).
Điểm chí tử: nút thắt cổ chai mạng trong xử lý dữ liệu song song
Ý tưởng DP khá đơn giản. Ví dụ bạn có 4 GPU, bạn chia một phân lô thành các phần nhỏ cho mỗi GPU, tỉ như, bạn chia một phân lô gồm 128 mẫu thành 32 mẫu cho mỗi GPU. Sau đó, bạn đưa các lô tương ứng qua mạng để có được khuynh độ cho từng phần đó của một lô dữ liệu. Sau đó bạn sử dụng MPI để thu thập tất cả các khuynh độ và cập nhật các thông số với giá trị trung bình tổng.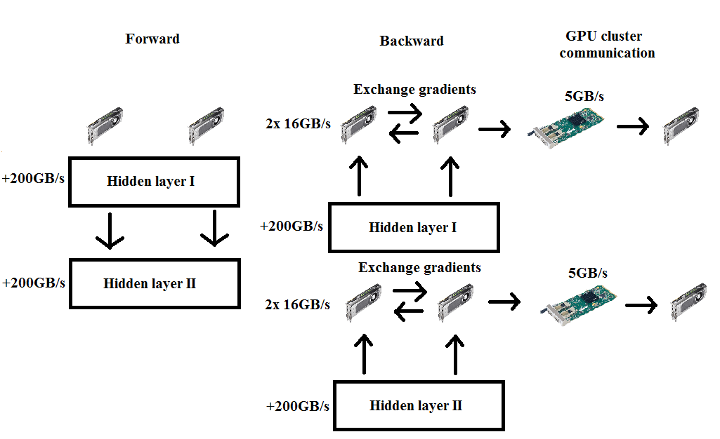
Sơ đồ xử lý dữ liệu song song DP. Không có giao tiếp bước tiến, còn trong bước lùi thì có đồng bộ hóa khuynh độ.
Vấn đề lớn nhất với phương pháp này là trong bước quy nạp cần phải chuyển toàn bộ khuynh độ sang tất cả các GPU khác. Nếu bạn có một ma trận trọng số 1000 × 1000 thì bạn cần đẩy 4 triệu byte cho mỗi hệ mạng. Nếu chúng ta dùng card mạng 40Gbit/s – cũng thuộc loại khá nhanh – thì cần ít nhất (4.000.000/40) x (1/(40x1024x1024x102)) x 1/(8×1000) = 0,75ms để chuyển dữ liệu giữa 2 nút xử lý cần phải giao tiếp đến được 5 GPU còn lại, 3 trong số đó cần phải đi qua các card mạng (3 x 0.75ms), còn 2 GPU có thể sử dụng PCIe 3.0 để truyền dữ liệu với hai GPU khác (sẽ nhanh hơn khoảng ba lần: 2×0.25ms). Do dữ liệu truyền qua cổng PCIe không liên quan tới card mạng, nên thời gian cần thiết để dữ liệu giữa 2 card mạng quyết định tốc độ chung và cũng đã là 2.25ms. Tất nhiên, chỉ một GPU có thể chuyển dữ liệu thông qua các card mạng tại một thời điểm trong bất kỳ một nút, do đó chúng ta phải nhân thời gian đó lên 3 lần, nghĩa là 7.75ms. Vậy mấu chốt là, chúng ta chỉ cần khoảng 0.2ms cho một ma trận dựng thông qua các lớp (100 × 1000 dot 1000 × 1000) và khoảng gấp đôi để quy nạp. Chúng ta có thể truyền giá trị khuynh độ trong khi chúng ta xử lý ở phân lớp kế tiếp, nhưng rồi thì về tổng thể thì tốc độ card mạng cũng sẽ giới hạn khả năng tính toán của chúng ta tương đối nhiều. Điều này càng rõ với hê thống có quy mô lớn hơn: Một hệ thống bốn nút xử lý trên cùng một bài toán cần khoảng 20.25ms để truyền thông tin khuynh độ đến được các GPU trong hệ thống. Dễ dàng nhận thấy tiếp cận DP không tăng theo được quy mô cụm nút xử lý.
Để giải quyết sự tắc nghẽn này thì phải giảm thiểu các thông số của khuynh độ bằng kỹ thuật tối đa hoá vùng chờ, tối đa số lượng đơn vị ấn định hoặc đơn giản nữa thì dùng tích chập (convolutional). Một cách nữa hướng tới để tăng tỷ lệ thời gian tính toán / thời gian kết mạng bằng các kỹ thuật khác, ví dụ như dùng tính toán tối ưu hóa chuyên sâu như RMSProp. Thời gian dành để chuyển các thông tin khuynh độ với nhau không đổi, nhưng dành được nhiều thời gian dành vào tính toán hơn, do đó tăng hiệu suất của GPU vốn có khả năng tính toán nhanh.
Một điều nữa có thể làm khi sử dụng các kỹ thuật tối ưu hóa tính toán chuyên sâu là làm ẩn đi độ trễ của mạng vào trong quá trình tính toán khuynh độ. Đại ý là cùng lúc bạn đi truyền thông tin khuynh độ đầu tiên cho tất cả các nút khác, bạn cũng đã bắt đầu một tính toán RMSProp lớn không đồng bộ cho lớp kế tiếp. Kỹ thuật này có thể giúp tăng tốc độ lên từ 0-20% tùy thuộc vào kiến trúc mạng.
Nhưng đây không phải là vấn đề duy nhất với xử lý dữ liệu song song. Tồn tại nút thắt cổ chai kỹ thuật ẩn ngay trong kiến trúc GPU khiến tôi mất khá nhiều thời gian để nắm bắt. Để hiểu lý do tại sao các kiến trúc GPU lại thành vấn đề thì trước tiên chúng ta cần phải nhìn vào cách sử dụng và mục đích của việc phân chia dữ liệu thành các phân lô nhỏ.
Phân kỳ: Tại sao cần phân lô dữ liệu?
Nếu chúng ta bắt đầu với các thông số khởi tạo ngẫu nhiên hoặc thậm chí nếu chúng ta bắt đầu với các thông số đã tập huấn máy trước đó, chúng ta không cần phải truyền tất cả các dữ liệu để có được một bản cập nhật chính xác khuynh độ vì kiểu gì chúng cũng sẽ bị giản thiểu cục bộ. Lấy MNIST làm ví dụ, nếu chúng ta có một khuynh độ trong đó bao gồm 10 sai lầm phổ biến mà mạng lọc ra cho mỗi lớp học (kích thước phân lô khoảng 128), thì chúng ta đã đang đi theo hướng làm giảm các lỗi đáng kể vì các lớp khuynh độ lọc bỏ lỗi thô và phổ biến. Nếu chúng ta chọn một kích thước phân lô lớn hơn (512 chẳng hạn) thì chúng ta không chỉ nắm bắt được những lỗi thông thường, nhưng cũng bắt được lỗi tinh vi hơn. Tuy nhiên, lại chả có nghĩa gì khi đi tinh chỉnh một hệ thống mà biết rằng nó vẫn còn đang mắc những lỗi lớn. Vì vậy, nhìn chung chúng ta việc tăng kích cỡ phân lô đạt được hiệu quả rất ít. Chúng ta cần phải tính toán nhiều hơn mà kết quả vẫn gần tương tự và đây là luận điểm chính vì sao chúng ta sử dụng một kích thước phân lô càng nhỏ càng tốt. Tuy nhiên, nếu chúng ta chọn một kích thước phân lô quá nhỏ, thì chúng ta không nắm bắt tất cả những lỗi phổ biến mà có liên quan để toàn tập dữ liệu và do đó khuynh độ của chúng ta không thể đạt được gần mức tối ưu cục bộ, vì vậy cũng có điểm tới hạn dưới cho việc chia các phân lô nhỏ đến mức nào thì vừa.
Tại sao điều này có liên quan đến DP? Nếu chúng ta muốn có một kích thước phân lô 128 và chạy DP để phân chia ra,ví như là, 8 GPU chẳng hạn, sau đó mỗi vòng tính toán giá trị khuynh độ trên 16 mẫu rồi trung bình hóa với các dữ liệu từ GPU khác. Chính đây là trường hợp kẹt phải nút cổ chai của phần cứng.
Mảnh ghép bộ nhớ (Memory tiles): Cấp phát vùng bộ nhớ GPU nhanh để có thể tính tích vô hướng hiệu quả
Để tính tích vô hướng trên GPU, bạn cần phải sao chép vùng nhớ nhỏ, được gọi là mảnh ghép bộ nhớ, vào bộ nhớ đệm dùng chung, vốn là bộ đệm rất nhanh nhưng kích thước rất nhỏ (giới hạn trong một vài kilobyte). Vấn đề là các cuBLAS tiêu chuẩn sử dụng mảng ghép bộ nhớ kích thước 64 hay 128 và khi bạn có một kích thước phân lô dữ liệu ít hơn 64 bạn sẽ lãng phí rất nhiều bộ nhớ dùng chung quý giá ấy. Ngoài ra nếu bạn sử dụng một kích thước phân lô không phải bội số của 32 bạn cũng đang lãng phí bộ nhớ dùng chung cũng theo cách như vậy (dòng xử lý chỉ được kích hoạt theo từng khối gồm 32 dòng xử lý), vì vậy hãy cố gắng sử dụng một kích thước lô là một bội số của 32 hoặc bội số của 64 nếu có thể. Đối với DP thực ra điều này khiến tốc độ xử lý giảm đi đáng kể khi cấp một kích thước phân lô dữ liệu nhỏ hơn 64 cho mỗi GPU. Nếu bạn có nhiều GPU,sẽ thấy rất khó tối ưu và đây là một lý do tại sao các phương pháp tiếp cận DP sẽ dừng lại ở một quy mô tới hạn nhất định.
Túm lại, điều này nghe có vẻ khá nghiêm trọng đối với xử lý dữ liệu song song DP, nhưng DP vẫn có các ứng dụng phù hợp của mình. Chỉ cần hiểu rõ những chỗ thắt cổ chai, bạn có thể ứng dụng linh hoạt DP như một công cụ mạnh vào thực tế. Điều này được minh chứng bởi Alex Krishevsky trong bài báo của mình, khi ứng dụng DP trong các lớp tích chập của Alex, và do đó đạt được sự tăng tốc 3.74x lần bằng nếu chạy trên 4 GPU và 6.25x lần khi chạy trên 8 GPU. Hệ thống của Alex có 2 CPU và 8 GPU trong cùng một máy, vì vậy ông có thể sử dụng tốc độ PCIe đầy đủ cho hai bộ bốn GPU và kết nối PCIe tương đối nhanh chóng giữa các CPU để phân phối dữ liệu lên tất cả 8 GPU.
Bên cạnh mạng nơ-ron tích chập (convolutional neural networks-CNNs), DP còn được dùng trong các mạng nơ-ron tái phát (recurrent neural networks RNNs), vốn yêu cầu ít thông số nhưng cập nhật thông tin khuynh độ tính toán rất lớn – cả hai yếu tố này đều là lợi thế của xử lý dữ liệu song song.
Trong bài blog tiếp theo của tôi, tôi sẽ tập trung vào mô hình xử lý song song MP, hiệu quả cho các mạng nơ-ron lớn và cũng trên quy mô các cụm xử lý lớn hơn.
(còn tiếp phần 2: Xử lý mô hình song song – Model Parallelism)